Nessun risultato. Prova con un altro termine.
Prodotti
Notizie
Topic
Offerte
Gadget e Device
Smartphone
Tablet
Smart Home
Imaging
Google
Microsoft
Apple
Tutto in Gadget e Device
Intrattenimento
Streaming
Videogiochi
Tutto in Intrattenimento
Software e App
Antivirus
VPN
Corsi
Web e Social
Tutto in Software e App
Business
Criptovalute
Finance
Tutto in Business
Trending
Perché TCL vende televisori di qualità a prezzi bassi
Apple premia l’eccellenza: ecco i vincitori degli App Store Award 2025
Netflix contro Chromecast
About
Redazione
Disclaimer
Informativa Privacy
RSS
Offerte
Gadget e Device
Smartphone
Tablet
Smart Home
Imaging
Google
Microsoft
Apple
Tutto in Gadget e Device
Intrattenimento
Streaming
Videogiochi
Tutto in Intrattenimento
Software e App
Antivirus
VPN
Corsi
Web e Social
Tutto in Software e App
Business
Criptovalute
Finance
Tutto in Business
Trending:
Perché TCL vende televisori di qualità a prezzi bassi
Apple premia l’eccellenza: ecco i vincitori degli App Store Award 2025
Netflix contro Chromecast
Gadget e Device
iRobot abbandona l'aspirapolvere: arriva Roomba Electro Plus, la lavapavimenti con AI
Domani
Mirsee MH3: l'umanoide industriale che arriva nelle fabbriche dal 2027
Prezzi e tariffe
Iliad fa faville con l'offerta dell'estate, ti salva anche le vacanze con pochi euro
Domani
L'intelligenza artificiale trasforma il lavoro nel 2026
Software e App
Due frecce sul simbolo del Wi-Fi: cosa significa questo simbolo nascosto sui telefoni Samsung
Smartphone
Exynos 2700: Samsung riprogetta il chip per dissipare il calore, addio RAM integrata
Gadget e Device
Smart TV Haier 50" 4K a 225,99€: Google TV, HDMI 2.1 e Dolby Audio al prezzo più basso mai visto
il meglio della settimana
Gadget e Device
Lefant M5 Pro a prezzo outlet su Amazon: 65% di sconto per il robot aspirapolvere e lavapavimenti
Smart Home
I robot aspirapolvere e lavapavimenti Lefant in sconto del 72% su Amazon
Gadget e Device
Robot aspirapolvere compatto con navigazione laser: Lefant M330 Pro in offerta a 139,99€ su Amazon
Software e App
Linea di Fiorano e AI: l’innovazione è nel DNA del marchio
Smart Home
Lefant M330 Pro: il robot aspirapolvere 3 in 1 è in offerta a prezzo stracciato su Amazon
Gadget e Device
Teclast lancia ArtPad Pro: tablet per creativi con display da 12,7" e funzione telefono
Gadget e Device
GEEKOM IT12: prezzo competitivo e super sconto -18% per il Mini PC
Gadget e Device
MiniPC con AMD Ryzen 7 in offerta: 20% di sconto sul sito ufficiale (CODICE SCONTO)
Web e Social
Questa pronuncia della Cassazione costringe Google al delisting delle notizie obsolete
Gadget e Device
Chuwi lancia GameBook: Ryzen 9, 32Gb di RAM e RTX 5070Ti a PREZZO FOLLE (Codice Sconto)
VPN e Sicurezza Online
VPN
Migliori VPN per Giocare a Call of Duty Modern Warfare 3 (2026)
Software e App
Recensione e Guida Surfshark VPN (2026)
VPN
Come Nascondere l'Uso di una VPN (Guida)
Software e App
NordVPN: recensione e guida (aggiornata al 2026)
Software e App
Offerte Black Friday 2024: le migliori VPN scontate
Software e App
VPN per PS4 e PS5: quale scegliere e come installarle
Motori
Un esperto del settore automobilistico sfata il mito: "Credo che questa sia ancora l'opzione migliore se si acquista un'auto usata"
Gadget e Device
14,99 da Esselunga e diventi bellissima: ti fa i capelli meglio del parrucchiere
Intrattenimento
La Nintendo Switch non verrà più prodotta: utenti increduli dopo l'annuncio, c'è la data
Smartphone
iPhone 18 Pro: le nuove batterie rivoluzionano il design
Prezzi e tariffe
Amazon lo ha fatto ancora: puoi comprare un iPhone nuovo a meno di 500 euro
Intrattenimento
Heidi live action: quando il cartone diventa realtà
Gadget e Device
Intel aumenta i prezzi dei processori Core Ultra 200S Plus
Business
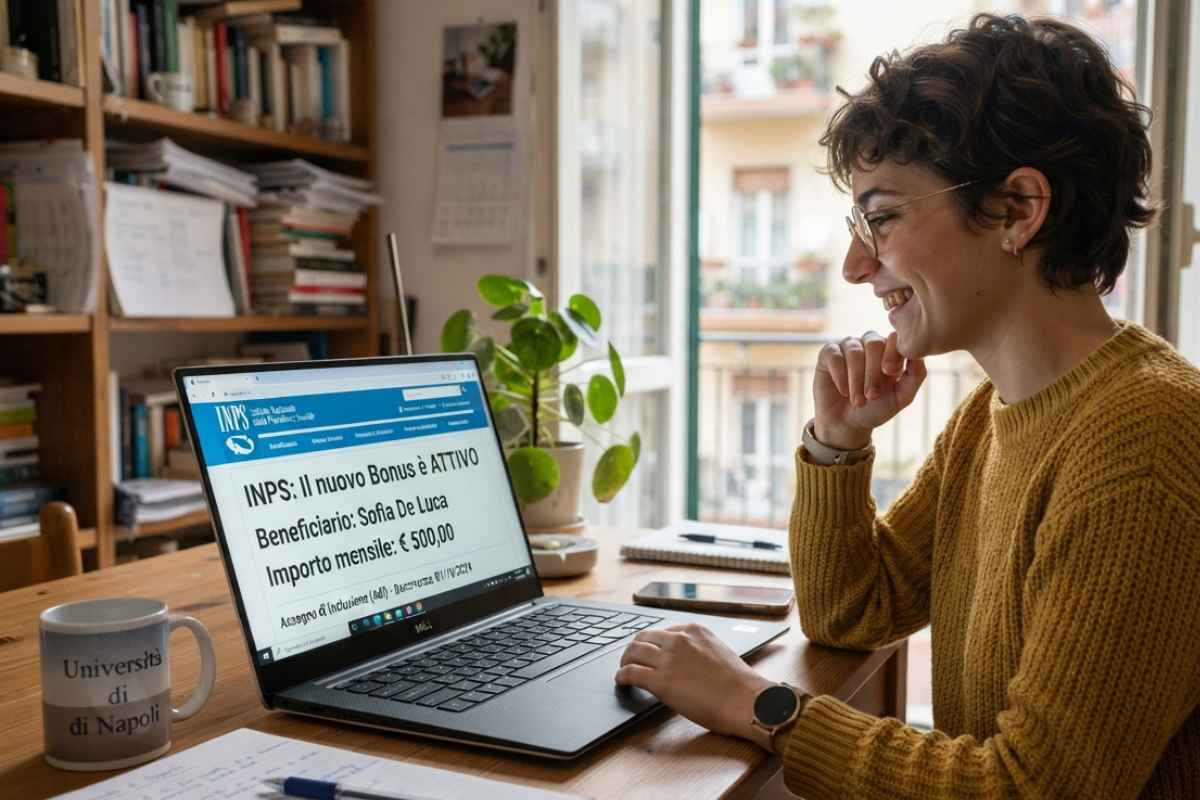
La novità annunciata dall'INPS: 500 euro al mese, il nuovo Bonus è attivo
Recensioni
tutti
8
Lenovo IdeaPad 3 con Ryzen 7: il laptop tuttofare da 500 euro
0
Arlo Essential: videocamera da esterno completa e versatile
7.9
Jabra PanaCast 20 4K: la soluzione ideale per le video conferenze
7.4
Nespresso Vertuo Pop: la nostra recensione
6.9
Hoover H-FREE 100: recensione dell’aspirapolvere senza fili
8.4
Catena di lampadine da esterno Govee: la nostra recensione
8.2
Luci a LED natalizie smart, la recensione di Twinkly Cluster
9
TCL C63 QLED TV: un ottimo TV al giusto prezzo
7.9
Oppo Watch Free: Recensione
8.7
Oppo Find X5 Pro: recensione completa
8.9
Lenovo Tab P11 5G: la nostra recensione
9.5
Google Pixel 6 | 6 Pro: i veri flagship Android
8.8
Lenovo IdeaPad Flex 5 Chromebook: la nostra recensione
9
GoPro HERO10 Black: la nostra recensione
9
Zhiyun Smooth 5 e Smooth X2: i nuovi gimbal per smartphone
9
Twinkly Strings (Generation II): l’albero di Natale diventa smart
9.1
Amazon Kindle Paperwhite 2021: il miglior Kindle di sempre?
8.8
Asus VivoBook Pro 14X
9.3
Amazon Fire TV Stick 4K Max
8.8
Nest Cam: la videocamera Made by Google
Gadget e Device
Sky verrà bloccata su alcune TV: i modelli coinvolti
Motori
BYD arriva in Italia: auto elettrica con 2000 km di autonomia
Gadget e Device
Juventus, le ultime trattative di mercato
Google
Google ammette: l'IA consuma troppa energia
Business
Unai Simón: il portiere che cambia il gioco della difesa
Gadget e Device
I miei auricolari costosi suonavano nella media finché non ho modificato un'impostazione audio di Android
Web e Social
Unai Simón
Web e Social
Alf-Inge Håland
Prezzi e tariffe
Chi lo avrebbe mai detto che il mio vecchio lettore DVD mi sarebbe fruttato 2000 euro
Business
Mercato Juventus
Software e App
WhatsApp nel 2026: le 5 funzioni che non conosci (e che ti cambiano la vita)
Business
Furbata al Bancomat: perché sempre più persone lo stanno facendo
Business
L'Aquila
Web e Social
WhatsApp attenzione, ora spunta la chat laterale: è piuttosto scomoda, così puoi evitare che accada
1
2
3
4
5
6
7
8
9
10
Change privacy settings
×














")

")
")
")
")
")