Nessun risultato. Prova con un altro termine.
Prodotti
Notizie
Topic
Offerte
Gadget e Device
Smartphone
Tablet
Smart Home
Imaging
Google
Microsoft
Apple
Tutto in Gadget e Device
Intrattenimento
Streaming
Videogiochi
Tutto in Intrattenimento
Software e App
Antivirus
VPN
Corsi
Web e Social
Tutto in Software e App
Business
Criptovalute
Finance
Tutto in Business
Trending
Perché TCL vende televisori di qualità a prezzi bassi
Apple premia l’eccellenza: ecco i vincitori degli App Store Award 2025
Netflix contro Chromecast
About
Disclaimer
Informativa Privacy
RSS
Offerte
Gadget e Device
Smartphone
Tablet
Smart Home
Imaging
Google
Microsoft
Apple
Tutto in Gadget e Device
Intrattenimento
Streaming
Videogiochi
Tutto in Intrattenimento
Software e App
Antivirus
VPN
Corsi
Web e Social
Tutto in Software e App
Business
Criptovalute
Finance
Tutto in Business
Trending:
Perché TCL vende televisori di qualità a prezzi bassi
Apple premia l’eccellenza: ecco i vincitori degli App Store Award 2025
Netflix contro Chromecast
Software e App
WWDC26, Apple cambia fase: l’intelligenza artificiale prende il posto dell’iPhone al centro della scena
Software e App
Ti rubano il telefono e tu lo autodistruggi con un SMS: come funziona il T-CREATE EXPERT P35SG
Motori
Aria condizionata in auto: tutti commettiamo questo grave errore in estate
Finance
Bitcoin verso il bottom di ciclo: i grafici indicano 125 giorni decisivi
Web e Social
Il Sistema Solare nascondeva un segreto? Scoperto il misterioso quinto pianeta scomparso
Google
Google Maps ha una modalità offline potentissima che quasi nessuno scarica
Software e App
Invece di spegnerlo normalmente dovresti provare a eseguire un arresto completo di Windows
il meglio della settimana
Gadget e Device
Lefant M5 Pro a prezzo outlet su Amazon: 65% di sconto per il robot aspirapolvere e lavapavimenti
Smart Home
I robot aspirapolvere e lavapavimenti Lefant in sconto del 72% su Amazon
Gadget e Device
Robot aspirapolvere compatto con navigazione laser: Lefant M330 Pro in offerta a 139,99€ su Amazon
Software e App
Linea di Fiorano e AI: l’innovazione è nel DNA del marchio
Smart Home
Lefant M330 Pro: il robot aspirapolvere 3 in 1 è in offerta a prezzo stracciato su Amazon
Gadget e Device
Teclast lancia ArtPad Pro: tablet per creativi con display da 12,7" e funzione telefono
Gadget e Device
GEEKOM IT12: prezzo competitivo e super sconto -18% per il Mini PC
Gadget e Device
MiniPC con AMD Ryzen 7 in offerta: 20% di sconto sul sito ufficiale (CODICE SCONTO)
Web e Social
Questa pronuncia della Cassazione costringe Google al delisting delle notizie obsolete
Gadget e Device
Chuwi lancia GameBook: Ryzen 9, 32Gb di RAM e RTX 5070Ti a PREZZO FOLLE (Codice Sconto)
VPN e Sicurezza Online
VPN
Migliori VPN per Giocare a Call of Duty Modern Warfare 3 (2026)
Software e App
Recensione e Guida Surfshark VPN (2026)
VPN
Come Nascondere l'Uso di una VPN (Guida)
Software e App
NordVPN: recensione e guida (aggiornata al 2026)
Software e App
Offerte Black Friday 2024: le migliori VPN scontate
Software e App
VPN per PS4 e PS5: quale scegliere e come installarle
Software e App
ChatGPT in Google Fogli, il nuovo rischio per i dati aziendali passa dalle prompt injection
Business
ISEE fino a € 35.000: il Caf spiega quali bonus si possono richiedere quest’anno
Software e App
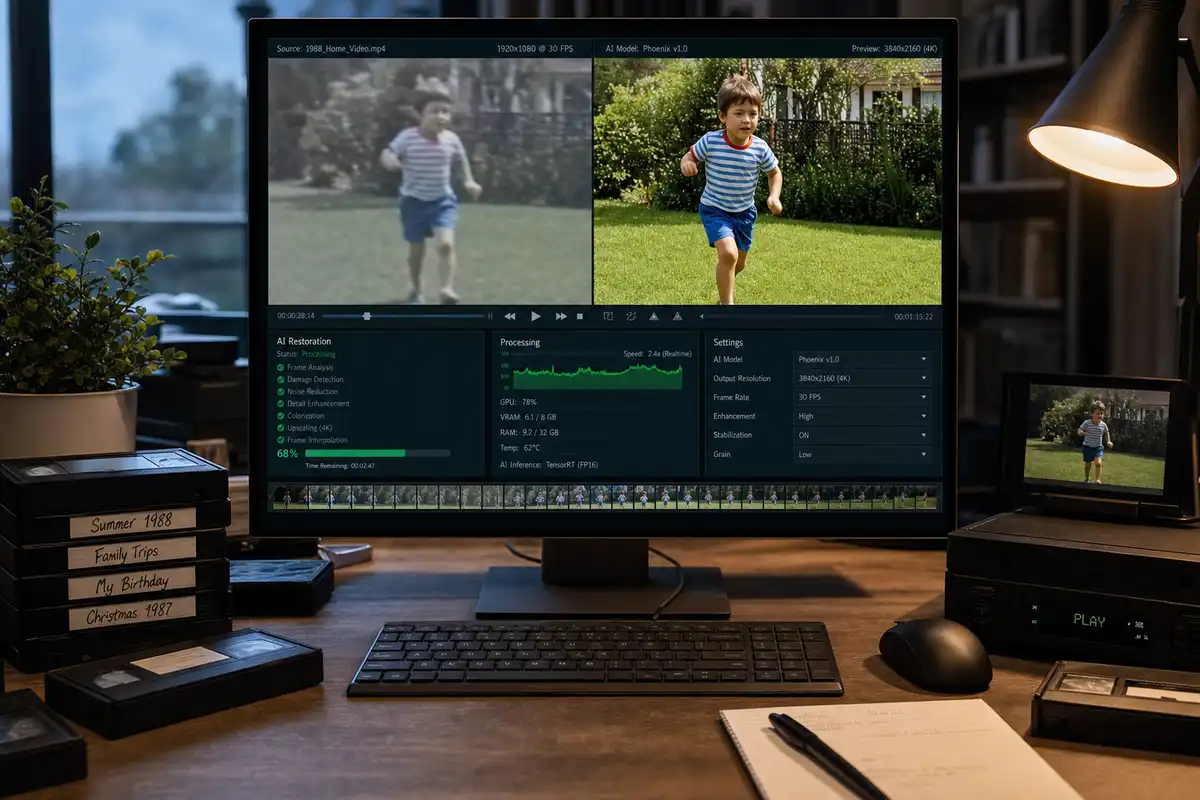
Come l’AI riporta in vita vecchi video sfocati: il caso Aiarty Video Enhancer
Gadget e Device
Il trucco per copiare un testo dal computer e incollarlo sul telefono all'istante
Gadget e Device
Lasci il caricabatteria nella presa e rischi tantissimo: il pericolo non è solo nella sicurezza
Gadget e Device
Ventoy contro Rufus: perché la chiavetta USB avviabile perfetta non esiste ancora
Business
Altro che buoni fruttiferi, chi vuole un rendimento elevato da Poste Italiane sceglie questo prodotto
Domani
AI, nelle aziende sta diventando pericolosa: quali dati sensibili vengono catturati dalla rete
Recensioni
tutti
8
Lenovo IdeaPad 3 con Ryzen 7: il laptop tuttofare da 500 euro
0
Arlo Essential: videocamera da esterno completa e versatile
7.9
Jabra PanaCast 20 4K: la soluzione ideale per le video conferenze
7.4
Nespresso Vertuo Pop: la nostra recensione
6.9
Hoover H-FREE 100: recensione dell’aspirapolvere senza fili
8.4
Catena di lampadine da esterno Govee: la nostra recensione
8.2
Luci a LED natalizie smart, la recensione di Twinkly Cluster
9
TCL C63 QLED TV: un ottimo TV al giusto prezzo
7.9
Oppo Watch Free: Recensione
8.7
Oppo Find X5 Pro: recensione completa
8.9
Lenovo Tab P11 5G: la nostra recensione
9.5
Google Pixel 6 | 6 Pro: i veri flagship Android
8.8
Lenovo IdeaPad Flex 5 Chromebook: la nostra recensione
9
GoPro HERO10 Black: la nostra recensione
9
Zhiyun Smooth 5 e Smooth X2: i nuovi gimbal per smartphone
9
Twinkly Strings (Generation II): l’albero di Natale diventa smart
9.1
Amazon Kindle Paperwhite 2021: il miglior Kindle di sempre?
8.8
Asus VivoBook Pro 14X
9.3
Amazon Fire TV Stick 4K Max
8.8
Nest Cam: la videocamera Made by Google
Software e App
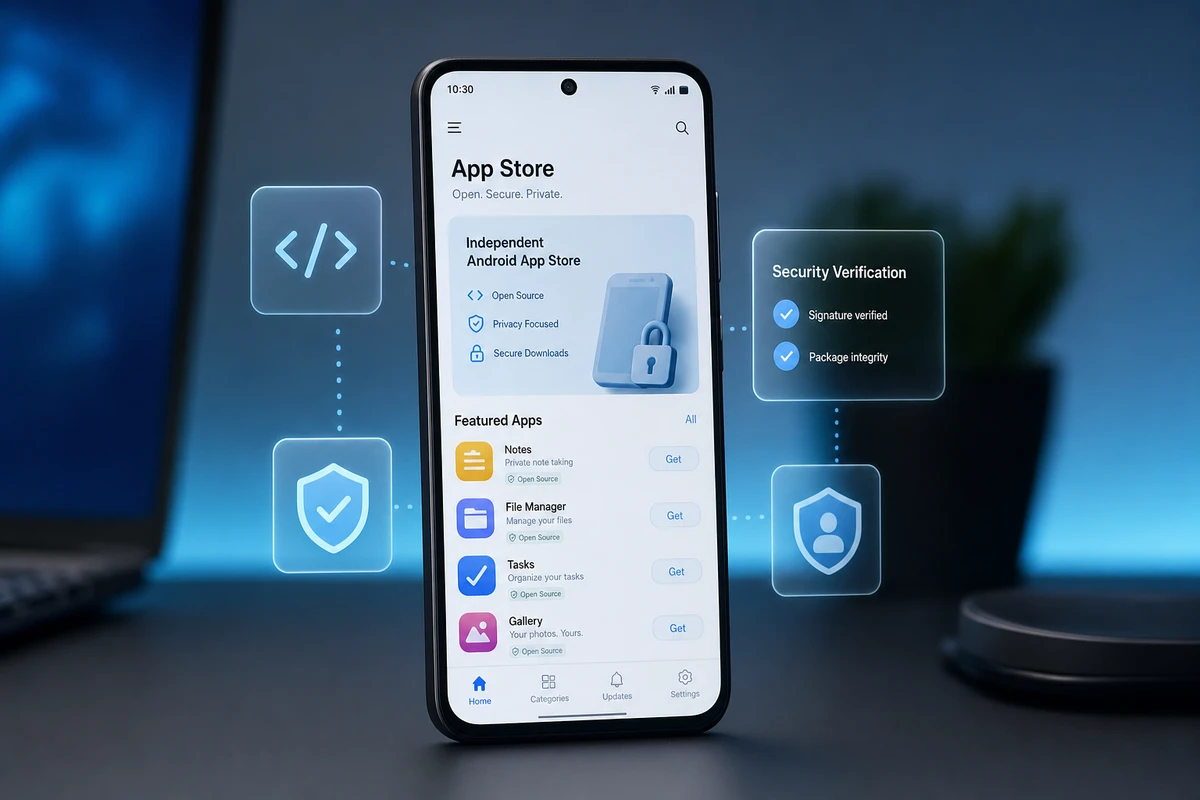
SafeHaven, l’app store open source che vuole rendere Android più trasparente
Software e App
La "tecnica mnemonica" per creare password il triplo più sicure
Intrattenimento
Palestra, la tecnologia sfida le buone maniere: come lo smartphone ha cambiato il modo di comportarsi in sala pesi
Motori
Auto elettriche, ora queste costano pochissimo: quale comprare subito per risparmiare nel 2026
Business
TF MasterCard Gold, la carta di credito per viaggiare: costi, coperture e vantaggi da conoscere
Gadget e Device
Ho trovato nella mia cameretta delle vecchie console Nintendo: le ho messe su Ebay e in un giorno ci ho fatto una somma inaspettata
VPN
VPN su iPhone e iPad: guida alla scelta, installazione e configurazione sicura
Business
Perché dovresti segnarti la data di domani sul calendario se vuoi pagare meno: c'è solo un giorno, poi è fatta
Software e App
Gmail e Instagram uniti dall'AI: Google lancia la nuova app rivoluzionaria
Software e App
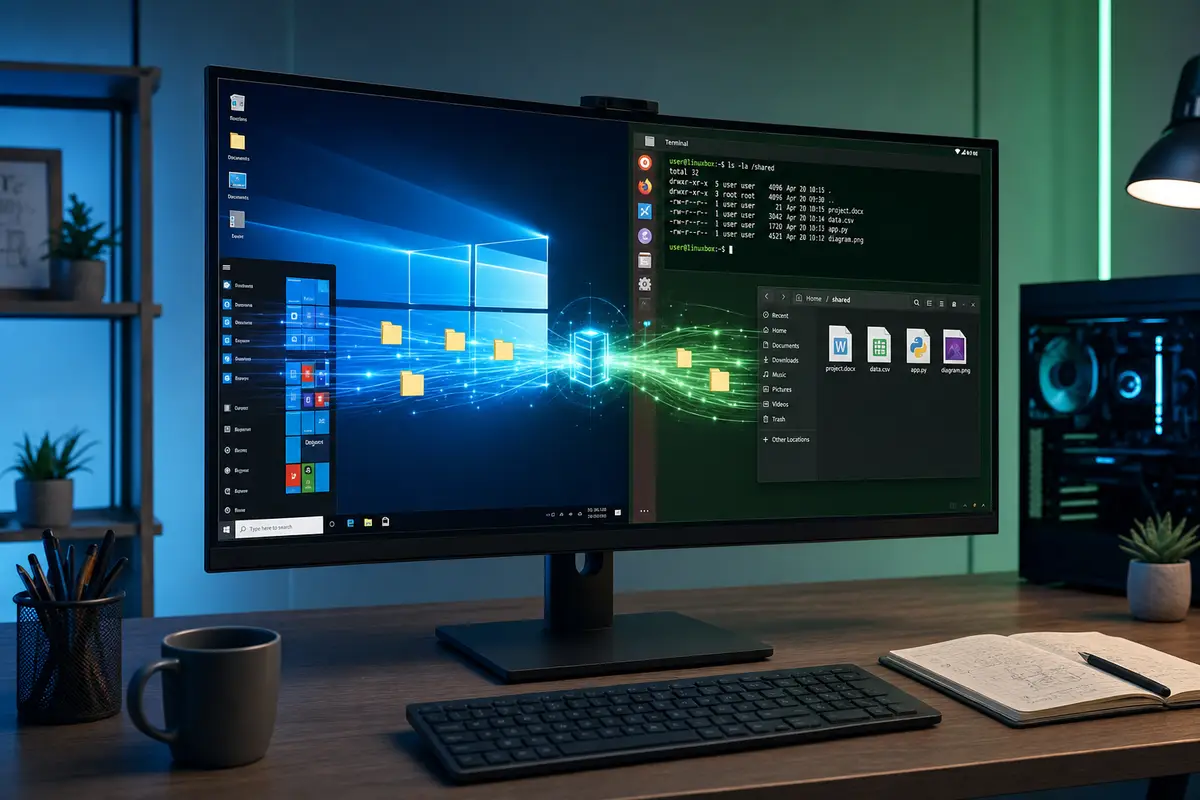
WSL 2 più veloce: Microsoft riduce la latenza nei file condivisi tra Windows e Linux
Gadget e Device
Leroy Merlin ci salva da zanzare e insetti con la soluzione geniale che costa appena 10 euro
Domani
Il robot modulare progettato dall’IA che sopravvive ai danni ma non ha ancora una vera missione
Gadget e Device
Modem, conosci la differenza degli indirizzi? A cosa serve l’IP pubblico e quello privato
Gadget e Device
HP porta la crittografia quantum-resistant sulle LaserJet: cosa cambia per PMI e grandi aziende
1
2
3
4
5
6
7
8
9
10
Change privacy settings
×














")

")
")
")
")
")